


Un día como hoy (30 de septiembre) pero de 1993, se presentó el primer motor de búsqueda para web: AliWeb.
Aliweb precedió, como idea y producto, a los dos iconos noventeros de la organización de la web: Yahoo y Google. A pesar de eso, y como suele pasar en la historia de los servicios web, ser el primero no bastó para lograr un éxito comercial, operativo o incluso incluso cultural. Y es que, ¿tú te acuerdas de Aliweb como lo harías de MySpace o Geocities?
Esta es su historia:
- La empresa de software Nexor tenía un desarrollador llamado Martijn Koster, quien en su tiempo libre y como proyecto personal (pero dentro del tiempo de trabajo) desarrolló un engine para organizar y catalogar los sitios web, que en 1993 eran muchos menos que hoy en día. Muchísimos menos.
- El proyecto empezó en 1992, se anunció públicamente en 1993 e incluso ya era usable en 1994.
- La interfaz era más parecida a un formulario que a la caja mágica de las versiones más conocidas de Yahoo o Google:
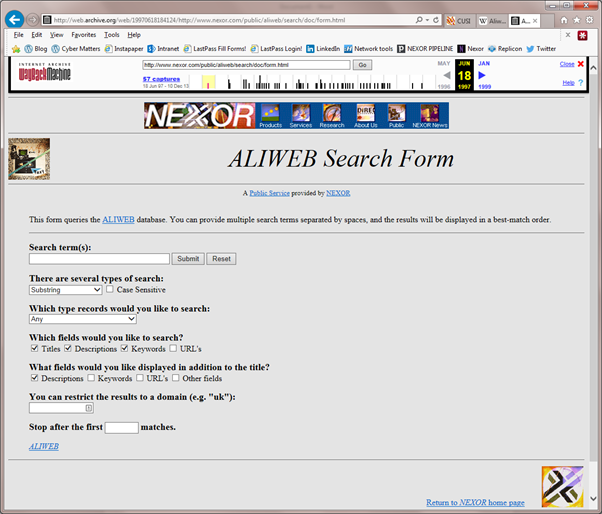
- Aunque de fondo había un engine que permitía organizar según criterios de búsqueda, en realidad no había un crawl bot o algo similar ya que más bien había curaduría humana para alimentar la base de datos.
- Incluso, en un ejercicio temprano de inteligencia colectiva, se invitaba a la gente a mandar sus propias entradas para la base de datos.
- La búsqueda web en esos tiempos era de especialidad, ya que debías elegir el buscador adecuado para tu tipo de consulta. Esto lo podemos apreciar en la temporada final de la serie norteamericana Halt and Catch Fire, donde un grupo de emprendedores propone a inversionistas el proyecto de un buscador para intranet de términos médicos. Esa tecnología es vista como prometedora por los portfolio managers y deciden tomar su base para aplicarla a la web en general.
- Posteriormente, Koster (el creador de AliWeb), inventó el concepto de robots exclusion standard, que es bastante parecido a como funcionan los buscadores modernos. Al contrario de una base de datos alimentada por humanos y curada, más bien hablamos de arañas que buscan por toda la red el contenido nuevo.
- Es gracias a Koster que tenemos robots.txt para evitar el crawling nocivo.








{kind=link}
Sin comentarios