

Bienvenid@s,
En el presente articulo se darán los principios de la solicitud de información a API’s, y como este impacta en el rendimiento de una aplicación en internet.
Conceptos básicos
API
Sus siglas vienen de TOpplication Programming Interfaces, y no es otra cosa que un conjunto de funciones en un sistema externo a las que puedes llamar desde tu propio sistema/navegador/app móvil, etc., y que por lo general devuelven algún valor o estado (Ejemplo: “Ok”, “Error”, Datos: {‘Titulo’: ‘Hola’}).
Tomando como ejemplo a la aplicación Whatsapp, cuantas veces no has querido entablar un chat con un representante de la empresa X, pero solo obtienes un chat con respuestas predefinidas que siguen un hilo de pregunta-repuesta muy especifico como:
- Escribe tu “Fecha de Nacimiento”.
- Entregas la fecha “2000/25/12”.
- Favor de respetar el formato “AÑO/MES/DIA”
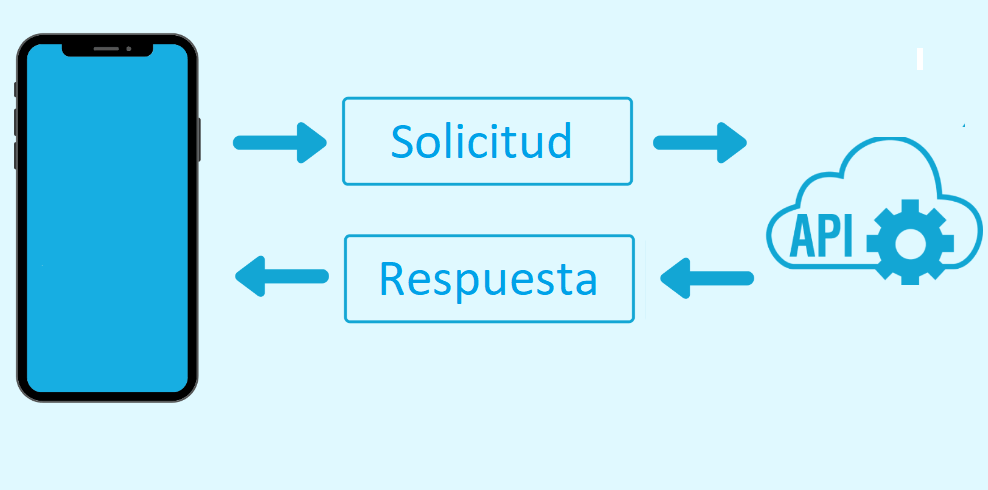
Fetch
Es una consulta a medios web/servidores/paginas/servicios externos que espera recuperar un valor o grupo de valores (por lo generar a un API).
Overfetching
Se refiere a hacer llamadas o recuperar información extra/adicional de un API, por ende no necesaria y que solo desecharemos o dejaremos sin uso.
Imaginemos el caso del sitio web de gobierno, cuando tu solicitas un tramite de CURP debes ingresar un grupo de datos, y esperas recibir una descarga de tú archivo CURP solicitado, pero también recibes información relacionada que probablemente es parte de tus datos ingresados previamente.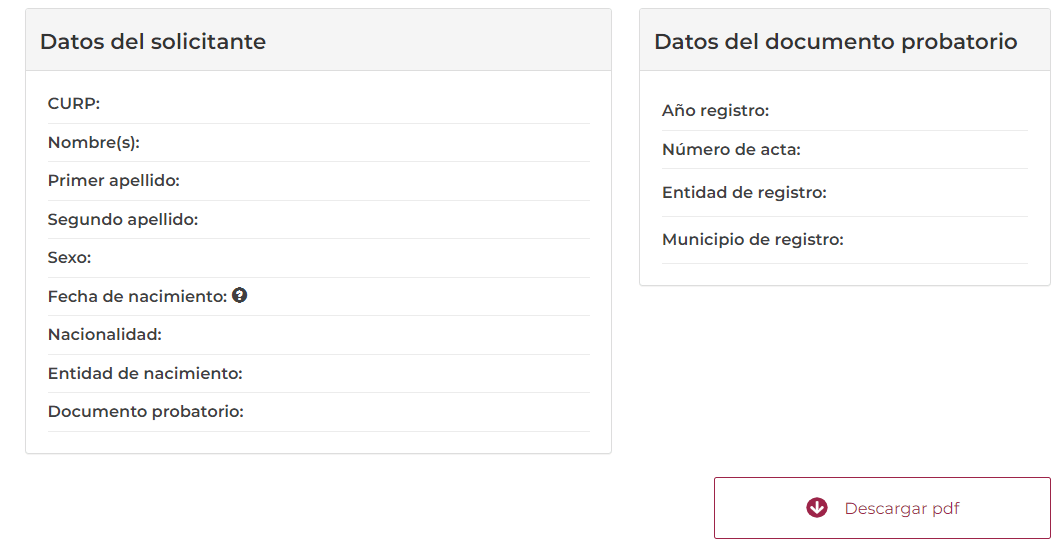
Underfetching
Se refiere a realizar llamadas a medios externos de los que se recupera información insuficiente o menos a la que se requiere para proceder a la sig. operación (registrar algún dato, borrar registros relacionados, etc.), esto significa que tendremos que volver a consultar por lo faltante y por ende demorar en concluir la actividad.
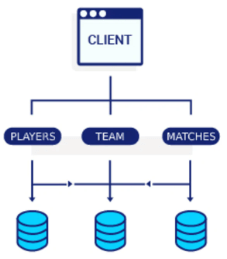
¿Cuál es el impacto del [Over/Under]Fetching?
En el caso de sistemas pequeños, implica el retorno de respuestas tardías o con información faltante que requerirá mas validaciones y confirmaciones de recepción, mientras que en aquellos de mayor capacidad, con cientos de miles de peticiones concurrentes, implica un problema real, ya que no solo no tardaran mucho en responder, sino que la cola de peticiones pendientes de atender será muy larga, y generara inconsistencias y cancelaciones al tratar de finalizar las transacciones/procesos consecutivos a la petición realizada.
¿Existe alguna solución a este problema?
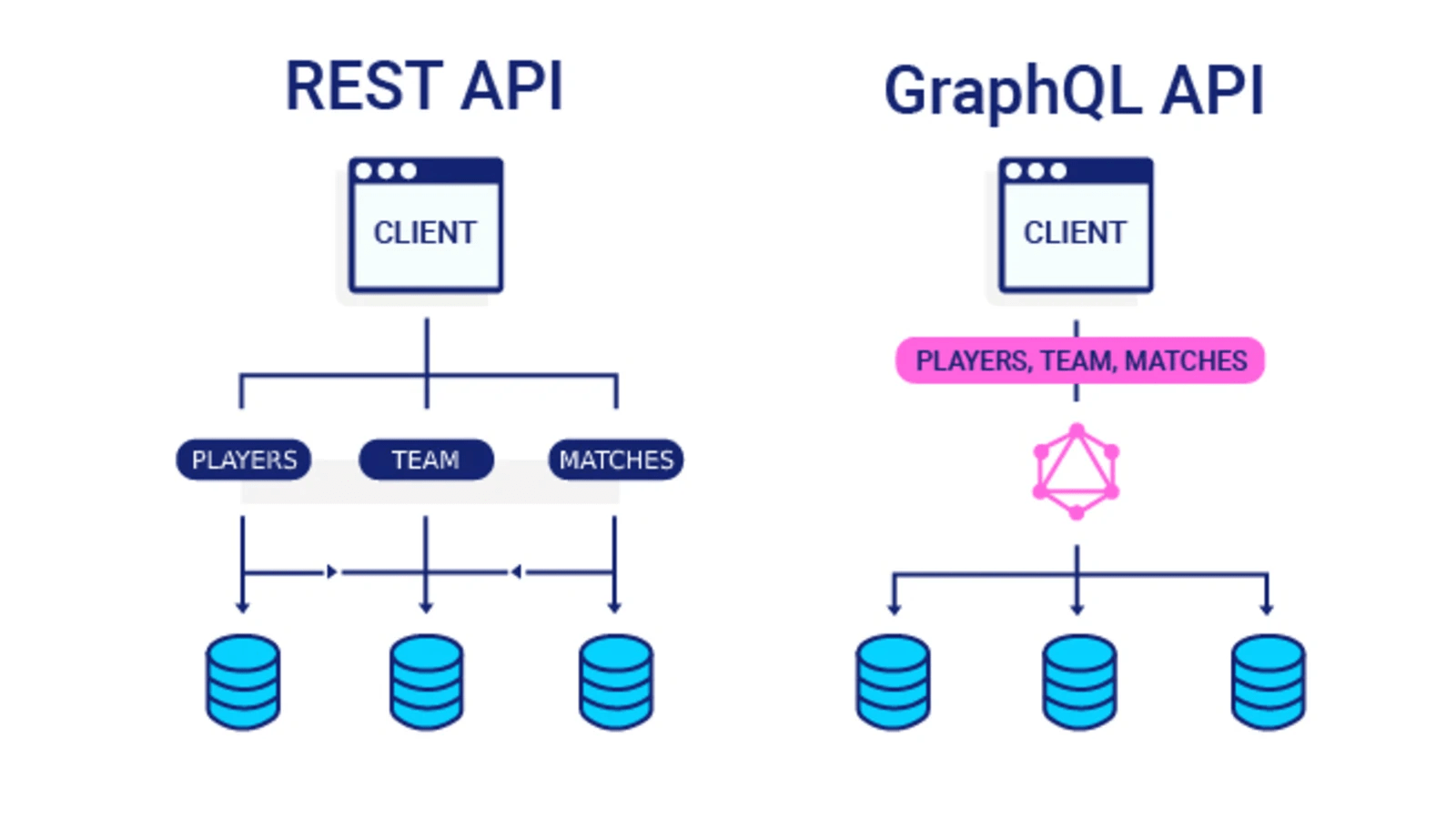
Una alternativa es el uso de la tecnología GraphQL, la cual permite que definamos la información a consultar (datos específicos y su tipo), de modo que todas las consultas se concentraran en este y por ultimo recibirás tus datos en un solo conjunto.
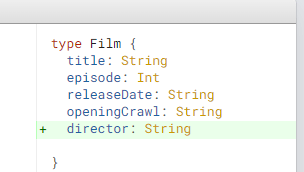
Adicionalmente tiene un soporte amplio para distintas tecnologías:
- JavaScript.
- PHP.
- Lenguaje Go.
- C/C++.
- C#/Tecnologías .NET.
- Lenguaje Python.
Por ahora este seria mi post, agradezco su tiempo.







{kind=link}
No Comment